“Calculation of energy flux in High energy Satellite” is my recently work on INTEGRAL catalog. My goal is to calibrate the emitting model and the interstellar absorption model in X-ray energy range. While the model is convincing, I can boldly utilize those models on HXMT catalog for estimation. The following notes are focused on Mathematica which I used to produce the data analysis.
Mathematica can read many types of data file, like .txt .dat .fits (It’s ok for read, but normally the capacity of FITS file are about 10MB, so it’s not ok for program running with such a huge burden), especially for large group of data analysis, this proper of mathematica is very useful. When talked about the fits file, there is a little trick I want to note down that I can use the Export function in fv tool to export the specific rows and columns with .txt for data analysis, instead of running the whole FITS raw data. Here’s the code for Importing files:
Import["complete path of your file","Table"]
I import data as table like {{1,2},{44,63}}. What is important to notice is the path syntax. For example, my OS X system have to start with a slash”/” and end up with file name, NO slash in the end.
eg. Import[“/Users/tuoyouli/Desktop/data.txt”,”Table”]
What’s next is exporting file which is similar with Import syntax.
Export["complete write path",data,"Table"]
eg. Export["/Users/tuoyouli/Desktop/HXMT flux/HEcounts.dat",Table[{b[[i]][[2]], b[[i]][[3]], a[[i]]}, {i, 1, Length[a]}], "Table"]
To explain this code let’s move to next section about reorganize data.
The previous Export code include a data reorganize part:
Table[{b[[i]][[2]], b[[i]][[3]], a[[i]]}, {i, 1, Length[a]}]
while a,b are two-dimensional data group like {{1,2,1},{3,4,3},{5,6,5}}, the b[[i]][[2]] is a coordinate that can pick the specific element of the group b. And based on this, you can pick up the specific elements in different data group and then reorganize them by code Table in anyway you like. Huzzah! Another interesting normal usage about reorganization, is to combine two lists on plotting. When I want to plot how groupA depends on groupB, I can write down this code:
ListPlot[Transpose[{A,B}]]
of course, listA and listB must in same length.
For this section is the key function for Mathematica. I was told the somebody believe the Calculation Physics is the third fundamental part of physics, the other two are theoretical and experimental physics. Wow, that’s huge! Anyway here’s the numerical calculation which can give out the numerical results instead of analytical results. So when talk about Numerical, two things occur to me. One, numerical integration. Two, fitting and interpolation values. For numerical integration in Mathematica, I can simply use the code NIntegrate[], this code contains different numerical integrate method like Monte Carlo. (for more detail read on NIntegrate Method) Another stuff is interpolate value for a experimental separated data to a curve or line.
eg. Interpolation[data,InterpolationOrder->3,Method->Spline]
This a 3-order spline to interpolate the data, also there are plenty of numerical method for interpolation. (Read More)
So, perhaps in the following career I don’t have much chance to use Mathematica, because Matlab takes the lead, you don’t really want to use the different syntax with people around you. But Mathematica is so elegant and so easy to use, this work was based on Mathematica which help me get through all the obstacles. And this work log may at least not be nonsense.

 , so the flux expression are given by:
, so the flux expression are given by:

 is photon index. Oops! My logic is a little bit chaotic right now, I should have introduce all the spectral models before calculating the flux utilizing those models. Anyway I’m not tend to list the mathematical expression of powerlaw, high energy cutoff, broken powerlaw, power.
is photon index. Oops! My logic is a little bit chaotic right now, I should have introduce all the spectral models before calculating the flux utilizing those models. Anyway I’m not tend to list the mathematical expression of powerlaw, high energy cutoff, broken powerlaw, power. 
 is the interstellar medium cross-section.
is the interstellar medium cross-section.
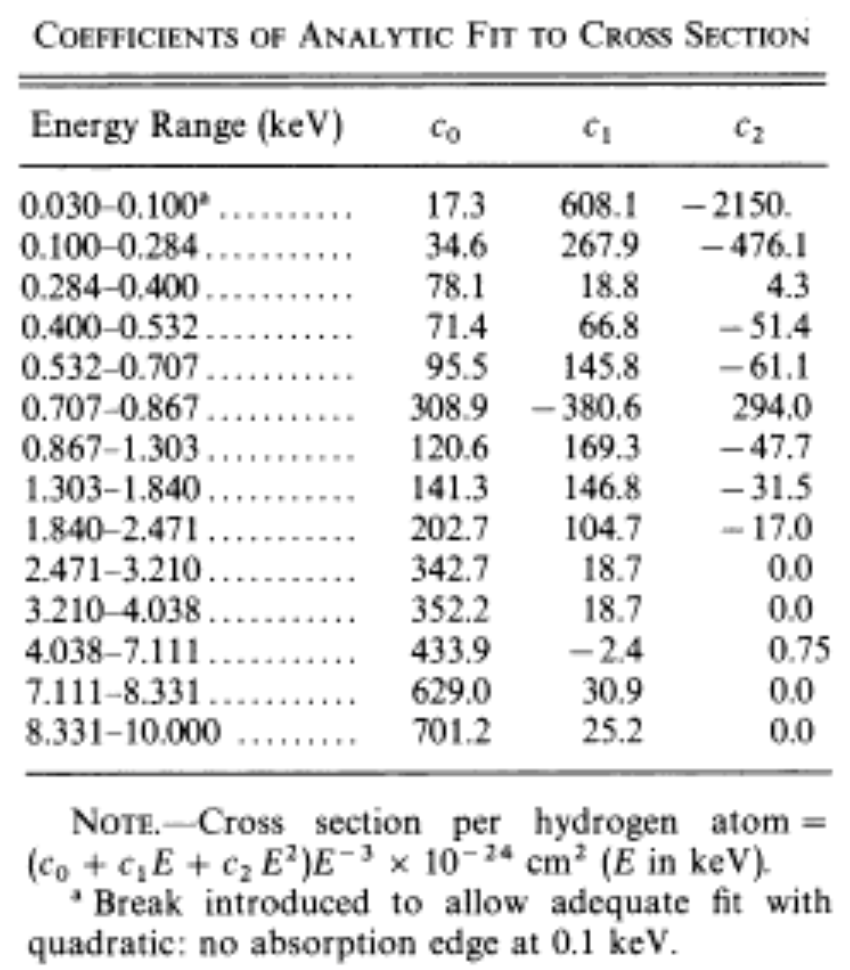

 and Mathematica’s
and Mathematica’s 


