在和龙曦讨论一个“置信水平”和“置信区间”的问题过程中,对于参数估计中的置信区间的报道有了新的理解,而之前的理解在遇到一些问题时会出现错误。这里首先讲讲参数估计中置信区间的问题,然后介绍Bootstrap的方法,并用Bootstrap抽样作为例子解释置信区间的问题。
一、区间估计(李惕培《实验的数据处理》)
待估参量 


若估计值 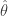
![[\theta-\Delta\theta_2, \theta + \Delta\theta_1]](https://s0.wp.com/latex.php?latex=%5B%5Ctheta-%5CDelta%5Ctheta_2%2C+%5Ctheta+%2B+%5CDelta%5Ctheta_1%5D&bg=ffffff&fg=333333&s=0&c=20201002)



将不等式移项可得

即:在估计值 ![[\hat{\theta} - \Delta\theta_1, \hat{\theta} + \Delta\theta_2 ]](https://s0.wp.com/latex.php?latex=%5B%5Chat%7B%5Ctheta%7D+-+%5CDelta%5Ctheta_1%2C+%5Chat%7B%5Ctheta%7D+%2B+%5CDelta%5Ctheta_2+%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Note: 在报道结果的时候,报道的是待估参量
二、Bootstrap 方法
若待估参量的样本有限,不能很好的反映待估参量的统计结果,则可使用Bootstrap方法进行抽样。用一组样本,进行重采样,得到基于这个样本的多个样本,对样本进行统计,得到待估参量的估计值。
举个例子。已知样本是 


若在 60% 的置信水平上,估计值 
![[\hat{\theta}-\Delta\theta_1, \hat{\theta}+\Delta\theta_2]](https://s0.wp.com/latex.php?latex=%5B%5Chat%7B%5Ctheta%7D-%5CDelta%5Ctheta_1%2C+%5Chat%7B%5Ctheta%7D%2B%5CDelta%5Ctheta_2%5D&bg=ffffff&fg=333333&s=0&c=20201002)

